
起因 微博用户@谷岳发布了一则探访狗不理包子王府井总店的真实体验视频,在网上引起轩然大波。 大概意思就是博主在大众点评上选择了一个口碑超差的狗不理包子店,亲自去体验下到底有多差。 体验一番并录制成视频发布到微博引起了广大网友热烈讨论。这时官方坐不住了,便发文表示“微博主谷岳未经餐厅允许发布与餐厅口碑不实的信息,蓄意抹黑王府井店铺并要求其撤回相关内容并公开道歉且已向北京市公安局网安部报警。” 后续 现在微博已经搜索不到王府井狗不理餐厅发布的相关声明了,估计是被喷太厉害,撤掉了。这下好,本来就一小群人知道的事情,全国人名都知道你家不仅做的不行,还不让消费者说。 将“解决不了问题就解决提出问题的人”的精神贯彻落实到底!
使用Django创建一个简单的个人博客
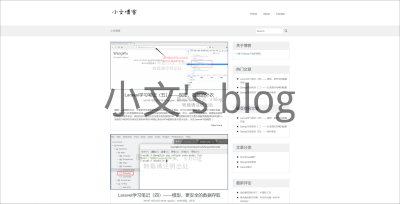
前言 小文在2018年学习Django的时候,有跟着教程做一个简单的博客demo,过了这么久,最近才想起要开源的事。索性改了下项目就直接开源啦。 简单的curd,仅供大家学习,如果真有博客使用需求的话,建议GitHub搜DjangoBlog那个项目。 个人认为学习一个新框架的最快方法就是上手去使用它,慢慢地就会发现框架其实大同小异,等你到了那种境界,基本就能举一反三啦。 预览 项目地址:https://github.com/qcgzxw/Django_Blog 演示地址:https://blog.qcgzxw.cn 管理员后台:https://blog.qcgzxw.cn/admin 首页 全站固定框架:上中下三部分。header body footer header固定显示logo footer固定显示本站说明 body部分分为两栏: 其中左侧显示文章列表,包括文章标题、固定尺寸的特色图、作者、发布时间、文章简介等内容。 右侧部分固定为工具栏,类似wp小工具。主要有关于博客、最受欢迎的文章(浏览量)、文章分类、最新评论、标签云和友链。 全局样式 有使用媒体查询优化不同窗口大小时的显示内容,具体表现为自适应wap和pc站点。 文章 文章部分同首页结构基本一致,仅在body部分有些许差异。 body部分左侧栏目则为文章,文章后紧跟分享按钮(暂未实现),然后是文章评论,最后跟着一个提交评论的表单 右侧则多了一个文章目录的小工具,便于读者快速定位到相关段落。 搜索 关键词搜索,会匹配文章标题、描述等内容。 分类、标签 评论 默认使用本站指定的头像,显示名称,评论时间等参数。仅允许一层嵌套。 后台 使用Django-Admin自动生成的后台,基本上没有样式,仅有简答的增删改查,适用于老鸟。 本地部署测试 篇幅过长,这里直接给GitHub的地址。 https://github.com/qcgzxw/Django_Blog#%E9%83%A8%E7%BD%B2%E8%AF%B4%E6%98%8E 更新日志 Ver1.0 项目初始化 最后 准备一直维护下去,有遇到bug或者需求都可以去Github提issue。 如果你能提交pull request,那是最好不过了。
Apple美区账号注册
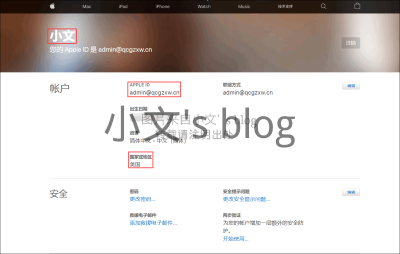
前言 众所周知,由于每个国家的法律不同,部分App在Apple Store上就会出现某个国家区域才有,而某个国家区域没有,比如小文使用的Spotify就无法在国区下载,于是,就会有共享ID这一说。 小文公众号就分享过美区共享ID,用于下载部分美区App,也是很受粉丝们欢迎,可共享ID使用的人数过多之后就会锁号,频繁锁号解号就会封号。。。于是, 小文今天本着授人以鱼不如授人以渔的心态就来教大家如何注册美区ID。 同理,可以使用该方法注册其他区(香港、台湾、菲律宾......)等等。 准备工作 苹果设备一部(iPhone、iPad都行) 电脑一台(Windows Mac都行,Linux系统不行 比如:Ubuntu好像不行) 国区(+86)手机号 邮箱(虽然很多临时邮箱,但是建议使用自己的邮箱) PS:小文建议个人用户使用自己的另外一个邮箱注册一个美区ID就行了,不要滥用,注册多了也没啥用,说到底就是个下载App的账号而已。 比如小文就是常用账号国区,新注册一个备用账号美区,用于下载App。因为共享账号由于使用的人太多,经常失效,应用一旦更新,账号失效的话,就无法更新App。 以上就是准备工作,缺一不可。有部分操作要在手机进行,有部分操作要在电脑进行。 详细步骤 我先总结下流程,部分熟悉Apple的朋友看完流程就大概了解了小文所说的意思,就能直接操作了。同样我也会给出详细的图文教程,供大家参考。 电脑网页注册国区ID,填好支付方式(无) 手机登录注册好的ID,成功下载一个App 电脑打开Apple ID网页,编辑付款方式,切换国家为美国 手机登录成功切换地区的ID,成功下载一个App 以上即为操作流程,有很多注意事项小文在接下来的图文教程给大家说明。 注册国区ID 打开Apple ID官网注册地址,填写信息注册账号 https://appleid.apple.com/account#!&page=create 登录到刚刚注册好的ID,填写假的支付信息 https://appleid.apple.com/#!&page=signin 最后点击存储,保存成功之后即可。 手机登录账号,下载App 首次注册的Apple ID需要验证才能下载App,所以我们登录到自己的Apple设备,下载一个App即可成功激活账号。 这里可能登录失败或者一直转圈圈,可以首先在网页端https://www.apple.com.cn/登录一下你的新ID,然后再用手机登录。 登录成功后,此时应该是国区Apple Store(中文),随便下载一个App,会提示输入密码,然后弹窗提示:这是你账号首次在Apple Store使用,请确认信息。之类的提示,然后按提示操作即可。 这步可能会有网络问题,删除Apple Store后台 重新登陆多试几次。直到成功下载第一个App为止 (重要)更改地址为美区/港区 打开Apple ID官网注册地址,填写信息注册账号 https://appleid.apple.com/account#!&page=create 和第一步一样,编辑付款信息,更改地区为美国,然后填写一个地址即可。 美国人信息生成 使用上面的网站随机生成一个美国人信息,然后把付款方式,账单地址全部改成这个地址,保存即可。 填写完成后点击存储,保存成功即可。 PS:如需更改为其他区,这里的手机号必须填成该区的区号,比如菲律宾: 852-XXXXXXX (随便填7位) (最后)登录Apple Store,换区成功 登录上你的Apple ID(已登录的点一下首页刷新一下状态),你就会发现Apple Store变成了英文版,一些国区下载不到的App,现在也是可以搜索并下载到。 随意下载一个App,这是会弹窗提示有新的隐私规则需要用户同意,同意后下载成功,完美结束。 注意事项 不要使用任何代理软件,直接注册就行。 文中提到的所有登录,仅仅是登录Apple Store,不是让你更换设置里的Apple ID。 可能是网络原因,登录Apple ID的时候,经常会一直转圈圈,Kill掉Apple Store后多尝试几次登录。 第一次登录账号时无法登录,可以现在网页端登录一下苹果官网。

爱奇艺十周年,年费会员只需79
为了庆祝 2020 爱奇艺十周年,这次又来了一个很不错的活动,没有门槛也不来虚的,直接 5 折优惠 99 元即可以购买一年的爱奇艺黄金 VIP 年卡! 扫描二维码进入页面再减20,79购买年费会员 爱奇艺 10 周年庆活动期间,黄金VIP会员、钻石VIP会员五折大促,黄金VIP会员年卡 99 元、季卡 29 元,钻石 VIP 会员 (支持电视)+携程超级会员年卡 330 元,点此可以前往购买。 十周年 VIP 会员半价特惠 这次的爱奇艺黄金 VIP 会员(原价198元/年),半价活动 99 元/年,不限购买次数 (用户可多次重复购买),但不包含「京东 Plus」 等第三方权益。 当然了,如果你主要是看剧而不太需要购物,那么这个价格显然还是超值的,特别是疫情期间大家都尽量选择呆在家里不出门,这时的影视 VIP 会员的优势就明显了。 另外,爱奇艺钻石 VIP 会员连续包年(黄金 VIP 的全部权益+ 支持 TV 电视端)+携程超级会员= 330 元/年,也不限购买次数。 79购买年费会员 复制活动链接到浏览器打开,然后绑定银行卡即可再减20!!! 会员区别: 爱奇艺黄金VIP会员:适用于手机、电脑和Pad,专享跳广告+蓝光1080P+杜比全景声,院线新片+热剧+独家综艺抢先看,付费影片VIP享半价优惠,VIP下载绿色通道(同时缓存5个视频)。 爱奇艺钻石VIP会员:支持手机、TV 电视、电脑和Pad,包含全部黄金会员特权+TV大屏权益。 取消自动续费: 优惠价购买会员默认情况下是自动续费的,如果你需要关闭自动续费,可以前往: 支付宝:我的→设置→支付设置→免密支付/自动扣款 微信:我→支付→右上角3个点(...)→自动扣费
你无法阻止应用程序“窃听”你的个人隐私
在网络世界中,个人隐私一向是用户在使用过程中考虑的重中之重。手机、电脑系统厂商也为此煞费苦心,尽可能在应用程序调用敏感系统权限时拦截并提醒用户。 iOS在个人隐私方面做的可以说是相当好了(全靠同行衬托),不少人摒弃安卓奔向iOS正是出于防止个人隐私泄露的考虑。 可即便是以系统安全著称的iOS系统近日也被曝隐私漏洞:数十个热门iOS应用程序在未经用户许可的情况下读取剪切板内容。 iOS剪切板内容遭泄露 安全专家Talal Haj Bakry和Tommy Mysk最新研究发现,数十款热门iOS应用程序在未经用户许可的情况下读取剪贴板的内容,而其中可能会包含一些敏感信息。 图片来自@www.macrumors.com 图片来自@www.macrumors.com 研究地址: Talal Haj Bakry and Tommy Mysk 以下是该篇研究的大概意思: 许多主流App,都会在启动时获取系统剪切板数据。 剪切板不仅仅只会泄露你复制的文本内容如密码或财务信息等,更会泄露你的精准位置信息。 当你开启通用剪切板后,这些应用程序还会读取到你从其他设备复制的内容。 [crayon-661eb1063276d672745750/] 小文想到的简单的应用: 获取你的精确地址来精准推送该地址的内容、或者该地址用户喜欢的内容给你 获取剪切板内容分析,猜出你的关注点来对你精准推送 在通讯录权限被禁止了的情况下,如果你的剪切板是11位数字而且疑似电话号码,将你和这个号码关联起来 有了这些剪切板数据和精准位置信息,应用场景太多了,我这只是浅层、有利的分析,更恶心的比如疑似密码搜集到社工库等这些我这里就不一一说了,再怎么说也只是猜测而已,留给大家深思吧。 苹果承包商通过Siri听到使用者语音 这是去年的新闻,截止至发稿应该已经修复(不敢肯定)。 Siri涉嫌暴露用户隐私事件缘起于2019年7月26日,英国《卫报》报道了Siri会在未经用户允许的情况下,将用户录音上传到服务器,并且发送给苹果外包的承包商进行人工分析。 据承包商透露,Siri记录下的内容包括了机密医疗信息,毒品交易,性行为的录音以及其它私人信息。 据《卫报》报道,这些泄露的录音片段,还会伴随着显示位置,联系方式和应用数据的用户数据等私人信息。不仅如此,承包商还表示,那些被听到的私人信息遭到滥用的可能性较大,因为对监听录音的工作人员能够自由查看数据,并没有接受过多的审查。 因此,在听到一些地址、姓名等信息时,想要识别具体用户并不是件困难的事。 然而,值得注意的是,对于Siri录音,且会聘请人工监听评分的这些事情,苹果公司并没有在用户隐私协议中明确说明。 在《卫报》报道中,苹果公司解释称: 为了改进Siri及其听写功能,Siri的一小部分请求会被用于分析,而用户的请求与用户ID并无关联。并且,Siri的响应是在安全的设施中进行分析的,所有的审查员都有义务遵守苹果严格的保密要求。 另外,苹果公司还补充道,只有一小部分随机数据(不到Siri每日激活量的1%)会用于评分,并且,那些数据通常只会有几秒钟。 今日头条未经用户允许获取用户手机通讯录被投诉 今日头条未经用户允许获取用户手机通讯录被起诉,辩称:通讯录不属于原告个人隐私信息。 该公司认为这不属于原告个人隐私信息,电话号码在日常民事交往中发挥信息交流作用,不但不应保密,反而是需要向他人告示。虽然通讯录中包含有个人姓名、电话等信息,但这些并非是原告本人的信息,而是其社会网络成员的信息,故该等信息不属于原告的“隐私信息”。 今日头条被诉侵权,辩称:通讯录信息不属于原告个人隐私信息 新一代窃听:无需获取麦克风权限即可完成后台窃听 当前智能手机 App 可在用户不知情、无需系统授权的情况下,利用手机内置加速度传感器采集手机扬声器所发出声音的震动信号,实现对用户语音的窃听。 可怕之处在于,这一攻击方式不仅隐蔽而且“合法”。也就是说,用户很可能在毫无感知的情况下泄露隐私,而攻击者并不违法。 浙大团队研究原文:https://mp.weixin.qq.com/s/ReAKUJhMAWMkVEwn5xT-oA 结论即是标题 你无法阻止应用程序“窃听”你的个人隐私,除非你不用。在国外某些发达国家出于儿童手表系统易被黑客攻击从而禁止所有儿童手表之后,国内某些家长甚至还把自己孩子拥有儿童手表作为炫耀的资本,不得不说,国民网络安全意识真的太差了。 国内个人隐私和信息安全方面做的是一塌糊涂,既没有相关法律法规,也没有相应的监管平台,更没有网络安全宣传和讲座。就更别提国民的网络安全意识了。 当然,这只是目前,我们相信将来一定会更好的。 国家也在出台相关法律法规来禁止这些不正当行为,已有法律的比如:《互联网个人信息安全保护指南》、《网络安全法》······ 太多太杂,法律咱也不懂,感兴趣的朋友可以去搜一搜。 当然,那些不觉得隐私泄露是回事的朋友权当我在放屁。

最新Windows漏洞——CVE-2020-0796,堪比永恒之蓝
永恒之蓝 2.0 来了,基于 SMBv3 的漏洞,Windows 8和Windows Server 2012 - Windows 10 最新版全部中招,属于系统级漏洞 利用这一漏洞会使系统遭受‘蠕虫型’攻击,这意味着很容易从一个受害者感染另一个受害者,一开机就感染。提权后可以做任意操作,例如加密你的文件勒索你。比如说像 EternalBlue 1.0 (永恒之蓝 1.0) 一样,加密文件,对你进行勒索虚拟货币! 在微软发布修补CVE-2020-0796漏洞的安全更新之前,Cisco Talos分享了通过禁用SMBv3压缩和拦截计算机的445端口来防御利用该漏洞发起的攻击。 CVE-2020-0796 这个漏洞编号CVE-2020-0796,与微软Server Message Block 3.1.1 (SMBv3)协议有关,在处理压缩消息时,如果其中的数据没有经过安全检查,直接使用会引发内存破坏漏洞,可能被攻击者利用远程执行任意代码。 这个漏洞被评为“ Critical”高危级别,攻击者利用该漏洞无须权限即可实现远程代码执行,受黑客攻击的目标系统只需开机在线即可能被入侵。 病毒危害 这个漏洞的影响程度据说堪比前几年的永恒之蓝,当年肆虐全球的“WannaCry”勒索病毒也是利用了SMB协议的漏洞攻击系统获得最高权限。 这个漏洞会影响目前主流的Win10版本,具体如下: [crayon-661eb106334b0706571470/] 不过Win7系统不受影响,这点跟以往的WannaCry病毒反过来了,后者只影响Win7系统,没影响Win10系统。 解决方法 好消息是,微软在3月12日的系统更新中,修复了改bug,win10用户只需升级到最新版本打上安全补丁即可 对于非win10最新版本的用户,建议手动在PowerShell执行以下代码来临时封堵该漏洞,使你的设备免受攻击管理员方式打开PowerShell,复制以下代码回车执行即可。 管理员方式打开PowerShell,复制以下代码回车执行即可。 [crayon-661eb106334c5189196761/] 如出现下图情况,则说明你的PowerShell软件非管理员模式运行。

关于浙江卫视《追我吧》和演员高以翔的一点个人看法
前言 首先声明,并非高以翔粉丝,也不是为了故意黑浙江卫视,就事论事。不喜勿喷! 真人秀猝死?我刚开始听到高以翔在参加浙江卫视真人秀节目猝死的新闻是不以为然的,我当时觉得肯定又是哪个大V在造谣骗流量。但是当我看到官方发布的最新消息的时候,彻底震惊了。 不禁思考,人的生命真的这么脆弱吗? 事情经过 11月26日21点30分左右,以翔和各位嘉宾开始录制《追我吧》第九期节目。以翔参与了两个小游戏,其余时间在主舞台观看其他嘉宾录制节目。 11月27日1点26分左右,以翔开始进行赛道环节录制。在奔跑了600多米并通过赛道上的装置后,他放缓步伐,坐在边上花坛,随后躺倒。此时为1点30分52秒。 发现异样后,跟随导演即呼叫现场待命的救护车,距事发位置较近的嘉宾也从主舞台跑向以翔。倒地后1分46秒,现场待命的宁波急救中心医护人员赶到并开始实施专业抢救。急救20多分钟后,救护车将以翔送往附近的三甲医院——宁波市医疗中心李惠利医院,经过2个多小时的全力抢救,院方宣布抢救无效。 死因 诱因:高强度工作 25日时高以翔在台湾出席活动,他和蓝钧天、吴建豪碰面,当时蓝钧天表示高以翔身体有点状况,“似乎是感冒了。”隔天( 26日 )高以翔早上8点30分仍敬业出席浙江卫视《追我吧》节目录制,直到晚间他的状况仍非常好,但节目一路拍摄到凌晨导致他身体不适。 高以翔好友透露,高从事故前一日(11月25日)早上8:30开始工作,一直到参加《追我吧》的节目录制到去世,整个17个小时没有休息。 外界因素:天气、时间 有专家援引《黄帝内经》中的观点,证明夜晚跑步是有损健康的!因为晚上运动扰动筋骨,汗出伤阳,可能会引起筋肉充血、脏腑亏虚。人会因此感觉越来越没劲,与运动的初衷背道而驰。 根据几千年来人的作息,不管是中医还是西医,都不建议在晚上进行高强度训练,更别说凌晨了。 再加上当时正是冬天,宁波夜间气温是在10℃以下的。在没有热身的情况下直接进行高强度运动,确实对人体很大伤害。 导火索:节目组! 节目组设计时要考虑嘉宾安全,这是基本要求。节目组在设计项目时没有排查所有可能对嘉宾有生命威胁的因素是本次事故的导火索。 虽说上面总总因素才导致高的不幸离世,但此次事故浙江卫视要负主要职责。 个人看法 首先对高的离世表示惋惜,其次严厉谴责浙江卫视《追我吧》栏目组的设计缺陷,最后喷一喷那些无脑踩浙江卫视舔湖南卫视的弱智儿。 不过貌似其他国家的一些真人秀更刺激(强制女生看自己被qj的视频之类的)但好像也没出啥事,只能说浙江卫视运气不好。。。录制了这么多期综艺节目,按概率的话,出一次事故也不算稀奇了。 浙江卫视出事,有些键盘侠就开始无脑喷浙江卫视,各种恶心的话都说出来了,还不惜拿出湖南卫视来做比较,搞得好像骂谢娜的那批人不是他们一样。甚至连高以翔名字都没听说过,就在网络上向浙江卫视讨命,真想送这些人几句
Vultr系统库已支持Centos8
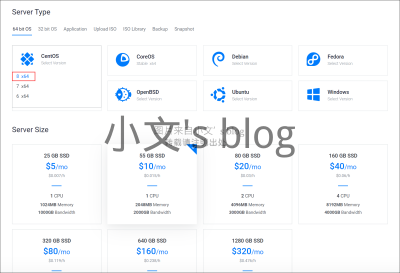
随着Centos8上周的发布,vultr目前也已经在系统库中加入了最新的Centos8,想要体验新系统的朋友快去试试吧! The world of operating systems is always changing - patches, new versions, and new concepts! With vultr's frequently updated library of operating systems, you can always be sure you have access to a wide range of OS images that can be deployed anywhere on our worldwide platform in seconds. 操作系统世界一直在变化-补丁,新版本和新概念!使用vultr经常更新的操作系统库,您始终可以确保可以访问在几秒钟内即可部署到我们全球平台上任何位置的各种OS映像。 Just last week, CentOS 8 was the latest image to be added to our OS library. The RHEL-compatible open source offering comes packed with new features and an updated kernel. Notable updates include a new package manager, new software repositories, updates to system applications, databases, programming languages, and much more. This Linux distro is also well known for…

今日头条被诉侵权,辩称:通讯录信息不属于原告个人隐私信息
“在我更换手机安装使用‘今日头条’APP并明确拒绝授权其读取通讯录时,该APP仍可向我推荐原手机中通讯录好友的联系人信息,在‘推荐’频道下仍可见原手机通讯录中的联系人账号。”刘先生称,这充分说明“今日头条”APP在未经其允许、未充分告知他的前提下,仍然保有其通讯录内容,仍可向其推荐之前的通讯录联系人。 认为“今日头条”APP在《用户协议及隐私条款》中未明确将收集用户个人信息,却擅自上传并保存其通讯录,严重侵犯了用户隐私权,违反了信息收集的“合理、必要”原则,用户刘先生当庭请求法院判令被告停止侵权、赔礼道歉并支付精神赔偿金1元。 上午,刘先生向法庭陈述,他在注册“今日头条”账号过程中,阅读过注册账号需同意的《用户协议及隐私条款》,在涉及用户个人信息的收集范围时,被告公司仅明确提出了在使用“今日头条”软件及相关服务获取信息的过程中,会涉及到“日志信息”、“设备或应用信息”、“位置信息”等用户个人信息类型的收集,但完全没提到该APP会读取或上传用户通讯录信息的情况。 “在我更换手机安装使用‘今日头条’APP并明确拒绝授权其读取通讯录时,该APP仍可向我推荐原手机中通讯录好友的联系人信息,在‘推荐’频道下仍可见原手机通讯录中的联系人账号。”刘先生称,这充分说明“今日头条”APP在未经其允许、未充分告知他的前提下,仍然保有其通讯录内容,仍可向其推荐之前的通讯录联系人。 刘先生表示,在未告知及说明的情况下,“今日头条”APP擅自上传其通讯录的行为严重侵犯了用户个人隐私。而通讯录信息作为极为敏感的个人信息类型,对个人的人身和财产安全等十分重要。《网络安全法》第四十一条中规定:“网络运营者收集、使用个人信息,应当遵循合法、正当、必要的原则。”“今日头条”APP是资讯推送平台,用户使用目的在于获取新闻资讯,而读取用户通讯录的行为让他不明其意义为何,“今日头条”的行为显然违反了“合理、必要”原则。刘先生认为,被告软件声称的智能算法不仅未充分提供资讯便利,而且让其个人信息、隐私更多暴露在网络,所以向法院提出上述诉讼请求。 但在法庭上,“今日头条”APP运营方北京字节跳动科技有限公司代理人提出,刘先生未提交充分证据证明涉案头条账号是由他实际使用的,也未证明出现在涉案头条账号添加好友页面推荐人列表中的用户是其通讯录联系人,属其个人隐私信息,因此刘先生并非此案适格主体,无权提起本案诉讼。 至于通讯录信息,该公司认为这不属于原告个人隐私信息,电话号码在日常民事交往中发挥信息交流作用,不但不应保密,反而是需要向他人告示。虽然通讯录中包含有个人姓名、电话等信息,但这些并非是原告本人的信息,而是其社会网络成员的信息,故该等信息不属于原告的“隐私信息”。 该公司还辩称提供服务过程中,读取、上传和存储原告的通讯录信息,事先已对其告知,且得到其明示授权,因此并不侵害其隐私权。 至记者发稿时,庭审还在继续。由于此案涉及互联网产业发展与个人隐私权保障的协调问题,对于智能算法、个人信息保护、智能APP产业发展等热点问题的调研、确立此类案件审判规则具有重要意义,因此备受关注。
vultr新闻:高频计算&新界面
今日,博主偶然访问vultr时,发现vultr界面大更新,以至于博主以为进了盗版vultr网站。流畅大气,简约美观,实在是太漂亮了! 难以置信,Vultr是在2014年2月推出的。从那时起,我们在16个数据中心部署了超过2300万个实例,Vultr团队努力使所有用户(从小型开发商到大型企业)都能轻松实现全球基础架构管理。 现在我们又推出了高频计算(High Frequency Compute)和新的面板! 新Logo 虽然我们喜欢上一个徽标的风格,但我们的团队已经准备好了一个全新的外观,更适合如今Vultr企业平台的特征。之后经过反复修改与迭代,最终选择了一种更加独特且易于识别的印刷和数字格式的简约外观。 当然,我们真诚地希望大家能和我们一样喜欢这个新Logo。新Logo可以在我们官网的资源文件页面下载。 新界面 首页 登录页面 个人页面 高频计算(High Frequency Compute ) 我们也很高兴能在云阵容中推出新的产品——高频计算(High Frequency Compute)!这款最新计划采用3 + Ghz处理器和超快的NVME存储技术,是Vultr曾提供的最高性能硬件架构。 高频计算(High Frequency Compute)能够为要求最苛刻的工作负载提供高达超过标准计算40%的存储和处理基准。 高频计算(High Frequency Compute)最初在新泽西州推出,将于今年夏天晚些时候在全球上市!阅读有关高频计算(High Frequency Compute)的更多信息或立即部署实例!

万能的AI之根据语音识别人脸
前言 近期,麻省理工CSAIL(人工智能实验室),最近就发布了这样一个让人难以置信的研究。只需要听6秒的声音片段,AI就能推断出说话者的容貌。 详细解释之前,咱们一起试试先。 听听下面这段录音,一共有六段。你能想象出来,说话的人长什么样么? 通过语音识别人脸 MIT研究人员,设计和训练的神经网络Speech2Face,就能通过短短的语音片段,推测出说话者的年龄、性别、种族等等多重属性,然后重建说话人的面部。 下面就是AI听声识脸,给出的结果: 左边一列是真实的照片,右边一列是神经网络根据声音推断出来的长相。 讲真,这个效果让我们佩服。 这篇论文也入围了今年的学术顶级会议CVPR 2019。 当然这个研究也会引发一些隐私方面的担忧。不过研究团队在论文中特别声明,这个神经网络不追求完全精确还原单一个体的脸部图像。 不同的语言也有影响。论文中举了一个案例,同一男子分别说中文和英文,AI却分别还原出了不同的面孔样貌。当然,这也跟口音、发声习惯等相关。 另外,研究团队也表示,目前这套系统对还原白人和东亚人的面孔效果更好。可能由于印度和黑人的数据较少,还原效果还有待进一步提高。 原理 从声音推断一个人的长相不是一种玄学,平时我们在打电话时会根据对方的声音脑补出相貌特征。 这是因为,年龄、性别、嘴巴形状、面部骨骼结构,所有这些都会影响人发出的声音。此外,语言、口音、速度通常会体现出一个的民族、地域、文化特征。 AI正是根据语音和相貌的关联性做出推测。 为此,研究人员提取了几百万个YouTube视频,通过训练,让深度神经网络学习声音和面部的相关性,找到说话的人一些基本特征,比如年龄、性别、种族等,并还原出相貌。 而且在这个过程中,不需要人类标记视频,由模型自我监督学习。这就是文章中所说的Speech2Face模型。 将电话另一端通过卡通人物的方式显示在你的手机上,可能是Speech2Face未来的一种实际应用。 模型结构 Speech2Face模型是如何还原人脸的,请看下图:给这个网络输入一个复杂的声谱图,它将会输出4096-D面部特征,然后使用预训练的面部解码器将其还原成面部的标准图像。 给这个网络输入一个复杂的声谱图,它将会输出4096-D面部特征,然后使用预训练的面部解码器将其还原成面部的标准图像。 训练模块在图中用橙色部分标记。在训练过程中,Speech2Face模型不会直接用人脸图像与原始图像进行对比,而是与原始图像的4096-D面部特征对比,省略了恢复面部图像的步骤。 在训练完成后,模型在推理过程中才会使用面部解码器恢复人脸图像。 训练过程使用的是AVSpeech数据集,它包含几百万个YouTube视频,超过10万个人物的语音-面部数据。 在具体细节上,研究使用的中每个视频片段开头最多6秒钟的音频,并从中裁剪出人脸面部趋于,调整到224×224像素。 之前,也有人研究过声音推测面部特征,但都是从人的声音预测一些属性,然后从数据库中获取最适合预测属性的图像,或者使用这些属性来生成图像。 然而,这种方法存在局限性,需要有标签来监督学习,系统的鲁棒性也较差。 由于人脸图像中面部表情、头部姿态、遮挡和光照条件的巨大变化,想要获得稳定的输出结果,Speech2Face人脸模型的设计和训练变得非常重要。 一般从输入语音回归到图像的简单方法不起作用,模型必须学会剔除数据中许多不相关的变化因素,并隐含地提取人脸有意义的内部表示。 为了解决这些困难,模型不是直接得到人脸图像,而是回归到人脸的低维中间表示。更具体地说,是利用人脸识别模型VGG-Face,并从倒数第二层的网络提取一个4096-D面部特征。 模型的pipeline由两个主要部分组成: 1、语音编码器 语音编码器模块是一个CNN,将输入的语音声谱图转换成伪人脸特征,并预测面部的低维特征,随后将其输入人脸解码器以重建人脸图像。 2、面部解码器 面部解码器的输入为低维面部特征,并以标准形式(正面和中性表情)产生面部图像。 在训练过程中,人脸解码器是固定的,只训练预测人脸特征的语音编码器。语音编码器是作者自己设计和训练的模型,而面部解码器使用的是前人提出的模型。 将实验结果更进一步,Speech2Face还能用于人脸检索。把基于语音的人脸预测结果与数据库中的人脸进行比较,系统将给出5个最符合的人脸照片。 不足之处 若根据语言来预测种族,那么一个人说不同的语言会导致不同的预测结果吗? 研究人员让一个亚洲男性分别说英语和汉语,结果分别得到了2张不同的面孔。 模型有时候也能正确预测结果,比如让一个亚洲小女孩说英文,虽然恢复出的图像和本人有很大差距,但仍可以看出黄种人的面部特征。 研究人员表示,这个小女孩并没有明显的口音特征,所以他们的模型还要进一步检查来确定对语言的依赖程度。 在其他一些情况下,模型也会“翻车”。比如:变声期之前的儿童,会导致模型误判性别发生错误;口音与种族特征不匹配;将老人识别为年轻人,或者是年轻人识别为老人。 参考文献 论文地址:https://arxiv.org/pdf/1905.09773.pdf 项目地址:https://speech2face.github.io/