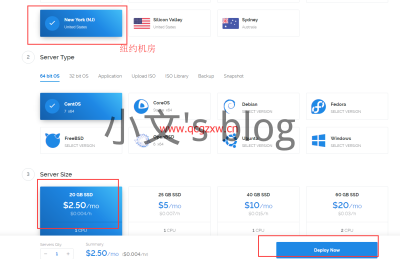
补货声明: vultr之前一直缺货的2.5美元KVM产品,重新补货,不过并不是所有机房都有货,目前补货的有纽约和迈阿密机房,不知道数量有多少,博主试了下速度还可以的,需要搭建$$和$$R的同学抓住机会。 相关链接:实战vultr搭建SSR+锐速——超速看youtube1080p 二重优惠 vultr最新优惠码之充10美元送10美元:充10美元赠送10美元(本链接长期有效) 主机测试: 当然vultr共有15个机房可供选择,其美国洛杉矶机房不错,日本东京机房对联通友好,新加坡机房对移动友好,选择5美元的的套餐也是挺不错的选择,而且如果觉得不满意可以直接删除VPS,毕竟vultr可以按小时收费的,需要的朋友可以试试看。 vultr官网测试信息: 法兰克福(德国) http://fra-de-ping.vultr.com/vultr.com.1000MB.bin 巴黎(法国) http://par-fr-ping.vultr.com/vultr.com.1000MB.bin 阿姆斯特丹(荷兰) http://ams-nl-ping.vultr.com/vultr.com.1000MB.bin 伦敦(英国) http://lon-gb-ping.vultr.com/vultr.com.1000MB.bin 纽约(美国) http://nj-us-ping.vultr.com/vultr.com.1000MB.bin 芝加哥(美国) http://il-us-ping.vultr.com/vultr.com.1000MB.bin 亚特兰大(美国) http://ga-us-ping.vultr.com/vultr.com.1000MB.bin 迈阿密(美国) http://fl-us-ping.vultr.com/vultr.com.1000MB.bin 达拉斯(美国) http://tx-us-ping.vultr.com/vultr.com.1000MB.bin 西雅图(美国) http://wa-us-ping.vultr.com/vultr.com.1000MB.bin 硅谷(美国) http://sjo-ca-us-ping.vultr.com/vultr.com.1000MB.bin 洛杉矶(美国) http://lax-ca-us-ping.vultr.com/vultr.com.1000MB.bin 悉尼(澳大利亚) http://syd-au-ping.vultr.com/vultr.com.1000MB.bin 东京(日本) http://hnd-jp-ping.vultr.com/vultr.com.1000MB.bin 新加坡 https://sgp-ping.vultr.com/vultr.com.1000MB.bin …
没有找到相关的内容
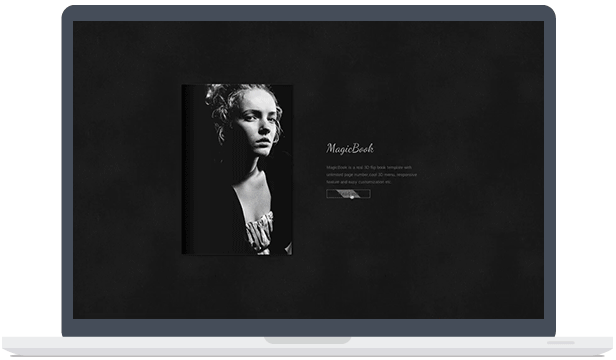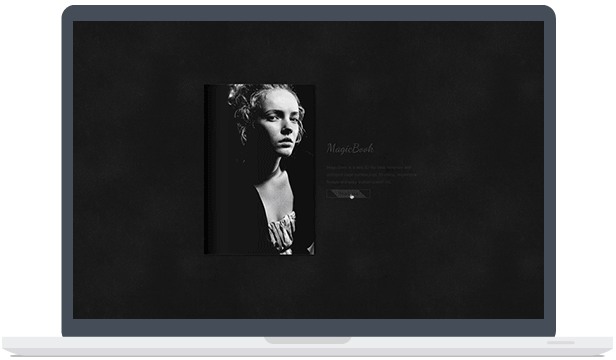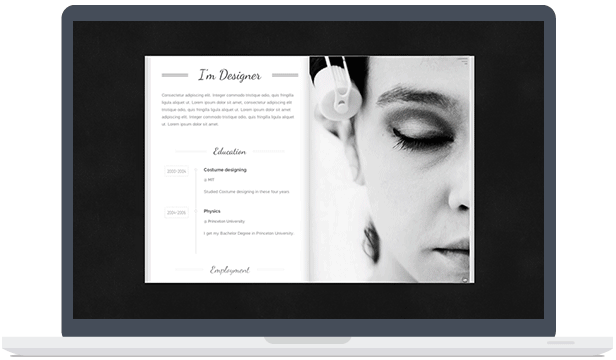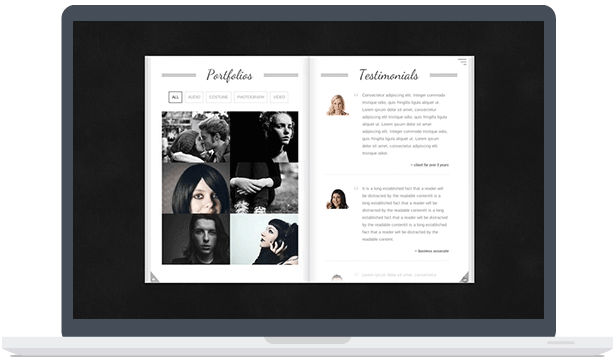
带有3D翻转书特效的WordPress图片企业主题
如果你是一名创意设计工作者,相信MagicBook这款主题一定会让你爱不释手。虽然他是英文的,但不可不承认的是,它优雅的设计会让你愿意花时间去将这款主题安装在你的wordpress上。 主题特点 3D菜单支持 支持可视化页面visual插件 优秀的自适应设计 WPML多语言支持 主题截图 下载地址

腾讯云年中大促,低至三折优惠
前言 站长朋友们注意啦,最近腾讯云活动不断,新出活动腾讯云年中大促,部分热销商品限时5折,更有年付三折优惠,现在购买服务器再合适不过了。已有腾讯云服务器的站长朋友也不要灰心,更有8585元升级/续费代金券礼包免费领!想搭建网游加速器的也可以参加秒杀(选香港机房),这价格是真的很便宜! 服务器作用 搭建个人网站(需要配合域名) 搭建网游加速器,机房记得选香港(教程移步https://www.qcgzxw.cn/2649.html) 搭建远程数据库 更多功能不一一列举! 活动详情 1.爆款服务器秒杀(推荐) 活动期间,每日五场(09:00, 11:00, 14:00, 16:00, 19:00)秒杀,入门服务器6个月仅需231元,高配服务器2年只需1313元。(需要蹲点抢哦) 2.续费/升级代金券大礼包免费领 需要续费或者升级配置的站长可以领一下,也可以参加上面的秒杀后再用这个升级优惠券升级服务器。 3.更多机型半价出售 活动地址 https://www.qcgzxw.cn/go/mid-year 后记 现在服务器域名越来越便宜,各大云服务器商也在拼命做活动助力全名上云。还在考虑想做站长的朋友可以搏一搏了,你不逼自己一把,你永远不知道自己的潜力。推荐几篇文章给各位站长朋友。 用虚拟机(vps)建站 如果你要建立一个WordPress的网站,你可能需要了解这几点 AMH面板配置ssl证书,http转https 低延迟吃鸡妙计——自建吃鸡加速器

爱奇艺年费会员只需178,再送一年京东plus会员
前言 前段时间和爱奇艺的小姐姐围绕着爱奇艺会员价格和用户体验这方面聊了大概一小时。聊了很多不外乎这几点: 1.怎样的折扣方案比较适合大众化(比如:拼团,返优惠券等方式) 2.怎么让用户知道爱奇艺的官方活动折扣 3.我对爱奇艺的看法与建议 这次借着爱奇艺的年费会员活动,一起发发我们聊的东西。 中途不止一次的提到过让他们的折扣加大力度,可别人明确说明为了正常的运营,不能一直做特别狠的活动。比如上次的半价年费会员活动,可能一年最多就一次这么大的折扣。 活动详情 活动很简单,178即可购买/续费 一年爱奇艺黄金会员,然后再送一年的京东Plus会员(可续费)。和上次的99的活动内容一样,没来得及上车的朋友可以勉强上这波车。要是觉得不满意,可以稍微等等,我们已经商榷了几个比较好的会员折扣方案,还请关注我们的微信公众号小文me和小文博客网站,我们将与官网同时推出,并详细讲解如何购买,是否值得买。 活动地址 网址入口: http://iqiyi.cn/c58Sa6h-6e5bde3d 二维码入口: 购买方式 点击以上网址或者扫描二维码后登陆你的爱奇艺账号 就可以看到默认已经选择了12月的套餐,点击确认支付即可。 然后购买后,赠送的京东plus会员在 我的 会员服务 我的VIP会员 购物权益升级里领取。 后期可能的折扣方式 我们暂时确定了以下折扣方式: 购买198元年费黄金会员返30元代金券。(这里的30元代金券只是比方,并不一定是30元,你可以把它当作X看) 通过奇艺盟会员邀请,直接便宜30元。 拼团价168购买年费黄金会员,然后分享你的拼团给另一个人,另一个人拼团成功后,才开通;若24小时内没拼团成功,则付款金额原路退回。 通过奇艺盟会员邀请,赠送明星周边门票或者实物(比如某某明星线下活动的门票之类的) 以上四种是我们商榷后觉得比较好的方案,小伙伴们觉得哪个好,可以在下方留言并说明观点。 再次重申,这些内容只是我们讨论的未来可能的几种方案,想要了解和得到最新的爱奇艺官方活动还请关注爱奇艺官网或者关注微信公众号 小文me ,我们将同步爱奇艺的所有官方折扣活动,并为你详细分析活动详情和是否值得买。

8月1号起微信这项服务将全面开始收费,你们准备好了吗?(内附免手续费提现方法)
前言 近日,网络上传出一篇“腾讯宣布8月1号微信所有功能将全部收费”的文章,不少网友信以为真,表示将不再使用微信。 昨日腾讯发布信息辟谣,实际情况是,我们只有一项业务开展收费,其他微信产品均不收取任何费用。 微信信用卡还款收费 那么这项收费服务究竟是什么呢? 自2018年8月1日起,对每笔微信信用卡还款按还款金额的0.1%进行收费(手续费的金额计算到小数点后2位,最低0.10元)。 每笔还款按还款金额的0.1%收费 对于手续费标准的此次变动,微信方面解释称,“每一笔还款背后都会产生支付通道手续费,为了使广大用户享受部分免费的产品体验,腾讯财付通一直在投入成本进行手续费补贴。近年来,随着信用卡还款业务的快速发展,通道手续费成本也在迅猛增长。腾讯方面表示,为了适当平衡成本和可持续发展,我们将对业务规则做出调整:自2018年8月1日起,每笔还款按还款金额的0.1%进行收费。与此同时,为感谢您一直以来的支持,我们将陆续推出手续费随机减免等活动。 也就是说,微信信用卡还款的月免费还款5000变成了,月免费还款0,每笔收费0.1%。 不少网友表示在提现手续费方面,支付宝一直都比微信要慷慨的多。 比起支付宝免费还自己和他人信用卡,微信真是有点抠门了。 依稀记得马化腾之前好像是承诺过微信永不收费的吧,自2016年起的提现收费到这次2018年的信用卡还款收费,这怎么解释。 好歹也学一学百度云呀,别人百度云刚开始就说了永不限速,后来人家改名百度云盘再收费,从道理上还是说的过去的! 微信免手续费提现方式合集 申请微信官方制作的收钱码,通过收款来增加免费提现额度。(具体规则请移步https://www.qcgzxw.cn/2533.html) 信用卡还款提现(2018/08/01后失效)。 成为微信理财通铂金或者黄金会员,信用卡还款不需手续费。 参与微信理财-爱定投计划,每月定投5000元以上即可免手续费还信用卡。 支付宝免手续费提现方式合集 信用卡还款提现(目前支付宝还没说要收费,再鄙视一波wx) 网商银行提现(余额转至网商银行再转至银行卡) 申请官方收钱码(可以用两个支付宝账号刷免费额度,再鄙视一波wx) 余利宝免费提现(余额转至余利宝再转至银行卡)