上文讲到emby支持电视直播,只需要设置IPTV直播源地址即可,也给出了博主自用的IPTV直播源文件。但是IPTV不同省份不同运营商有区别,所以适用于我的IPTV直播源可能不适合大家,所以本文将教大家如何找到/制作适合自己的直播源文件。本文涉及一些专业知识,请提前做足功课。 战前准备 IPTV地址获取 博主是在Github找到有人分享的全国各地的持续更新的IPTV地址,然后筛选出能用的地址,制作转换成m3u文件。 全国IPTV地址:https://github.com/SPX372928/MyIPTV 下载整个项目之后,使用直播源列表工具TeleList,将你想要测试流畅度的源转换成Potplayer可以识别的播放列表。 IPTV地址测试 博主是使用Potplayer测试频道连接状态和流畅度,再通过IPTV Checker过滤失效的频道。 TeleList会在同目录下创建一个m3u格式的文件,拖到Potplayer程序里,就能测试能否可以播放以及流畅度了。 找一个能够快速播放不卡顿,且流畅清晰度还不错的m3u文件,再通过IPTV Checker过滤掉无法使用的频道即可。 检测完成之后,选择可用的频道导出新的m3u文件。此时的m3u文件再次通过potplayer打开可以看到,应该是所有频道都能正常播放的。 频道筛选、重命名 最终经过IPTV Checker筛选的m3u文件,虽然都是可以正常播放的频道,但是里面可能会有不同清晰度的相同频道或者你不想要的频道,这时,使用文本编辑器打开该文件,删除不想要的频道即可。 m3u格式两行为一个频道,上面一行保存频道信息,下面一行保存频道直播地址 删除频道要删掉两行。 删掉不想要的频道之后,为了能更好的适配logo,这里还需要对频道进行改名处理。 例如:CCTV1 3M1080 改为 CCTV1 最终处理得到的m3u文件如下: logo匹配 这里推荐使用:http://epg.51zmt.top:8000/ 只需上传你的m3u文件,它会自动帮你匹配频道信息,logo。(上一步的频道改名就是为了该网站能够识别频道信息) 最后生成的m3u,便可以直接用作emby电视源了。 emby设置 将m3u文件上传到emby服务器,在服务端设置emby直播源时选择该文件即可。 直播源设置完毕,需要设置电视指南来获取频道节目信息。具体内容可参考上一篇文章 至此,emby电视直播设置完毕,效果图如文章第一张图所示。

Emby设置IPTV电视源看奥运会
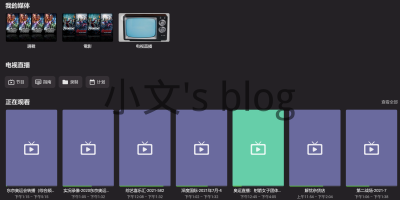
Emby支持设置IPTV地址来观看电视直播,也有很完善的节目单以及电视录制等功能,很适合用来观看奥运会直播。 IPTV全名网络协议电视,是宽带电视的一种,部分是和宽带一起捆绑销售。而这些IPTV直播地址,理论上我们是可以通过抓取每个节目的直播地址,来实现跳过电视盒子/软件直接在电脑或手机观看直播的。 Emby刚好对电视直播支持比较友好,便花了点时间整理了一份用于emby的电视直播源文件,放在GitHub。本文将分享博主自用的IPTV直播地址以及Emby设置方式,更有进阶篇适用于动手能力较强的小伙伴。 IPTV电视源 博主根据GitHub上整理的IPTV链接,自己选了一套适合广州联通的路线并放在GitHub。 广州联通自用IPTV:https://github.com/qcgzxw/MyIPTV 根据博主的GitHub链接readme说明,添加M3U电视源即可。 https://raw.githubusercontent.com/qcgzxw/MyIPTV/main/emby.m3u 此时在首页就能看到添加进去的电视频道了,如果没有Emby Premiere会员,会提示功能无法使用。直接购买或者参照上文链接破解即可。 正常展示如下 点击相应的频道,等待几秒即可直接播放 频道信息/电视指南 添加完成之后,可以直接观看,可我们要达到向电视盒子一样,能有节目信息的话,就需要设置节目指南。 直接在Emby设置里添加一个指南数据源即可。 然后选择任意国家,指南源选择XmlTV即可 然后设置指南源:http://epg.51zmt.top:8000/e.xml 其他信息默认即可 保存后,会自动更新节目指南,更新完成之后,再次回到主页,就能达到本文开篇的那两张图一样,有节目信息。 常见问题 节目信息和正在播放的节目对不上。 这个问题一般是服务器时区问题,设置服务器时区为Asia/Shanghai即可。 节目录制功能 Emby自带节目录制的功能,可以保存你想看的剧集到本地,供你日后再看。 自定义IPTV地址

当阿里云涉嫌侵权,还直接从客户变成竞争对手,你会怎么办?
我现在抱着长久的愤怒、不甘、更不相信的复杂心境之后已然平静的心情,来写这篇文章,也许你会认为标题党,看完也许你就知道非常的名副其实。 按照老罗的规矩,还是先要自夸一下。 这是我在六月初的亚太 CDN 峰会上做的公司介绍,我相信都是真实的情况,而且实际上还至少忘记写了一项,就是我们在 2014 年推出商业版本的时候,就是率先给客户发布每日(商业合同上会写每个工作日,但实际上基本上做到了每天更新,持续至今)更新的 IP 库,之前的同行都是按周或者按月更新的。我写的是领先,其实是不想违反广告法。 用我们数据的人应该会记得,我们在 2015 年底的时候,数据库行数只有 23 万行,到了 2017 年底,我们就有了 287 万行的数据了。目前呢?可以看一下最近一年左右的情况: 联合 IPv4 和 IPv6,在 2020 年 6 月 底,我们有 685 万行数据,而截止到 2021 年 7 月 13 日,我们已经有了超过 826 万行数据了。这仅仅是增加的行数,还不算我们每天修改的数据,实际上,在我们大部分工作日时间,每天都会修改超过 10000 行的数据。我就不啰嗦这个了,有兴趣的可以自己看:https://www.ipip.net/stats/ipdb.html 我在之前的公众号文章里引用过这样一句话,“不用扬鞭自奋蹄”。我相信我和我的团队做到了。虽然也有各种不满意,我依然为我们整个团队骄傲,无论是现在的还是离开的。 好话说完了,开始说正题。 IP 地理位置数据库,作为一个非常细分的领域,也是一个寂寞甚至很容易被人误解的领域,我之前也非常愿意和对这个领域感兴趣的业界同仁分享一些知识,但是今年开始,恐怕不会了,为什么?请看完下文。 去年年初,突然的疫情,加上之前天花板问题导致我们深思熟虑后的商业模式的变化,我们作为小公司,自然需要全力应对这两个事情,一方面要在技术方面要继续保证数据质量有竞争力,并且还要不断推动数据的全球化,一方面在商务方面要应对客户的问询甚至是刁难。 去年三月的一天,一个朋友跟我在微信上问我,某大厂近期也发布了一个 IP 库,你们会有压力吗?我当时应该是抱着良性竞争的想法,跟他聊了两句,大意是“好啊,如果总是只有我们在做,那多寂寞啊,如果有大公司愿意参与,也许是好事呢。”我跟我同事转述了这个事情,我同事却跟我态度不同,他觉得恐怕没那么简单,毕竟它还是我们的客户(虽然在合同中已限定单一用途)呢。我虽然心里打着鼓,但是嘴上却说要相信大公司的内控。 多说一句,我们目前的离线库销售都是必须要签商业合同的,里面必须有的几条,未经许可,不得转售,不得对外提供查询服务,不得用于合同约定之外的用途,否则你给我再多的钱,也不会卖给你。 到了 8、9 月份的一天,我同事跟我说,貌似他在某大厂发布的数据库里能找到很多数据和我们的数据相似度极高,眼看着就是复制粘贴,我亲自翻了翻,甚至是有我亲自制作、修正的数据,里面也有非常细碎的数据,不是靠网页查询可以做到的。 各位一定要先理解一个道理,就是 IP 库其实并不是一个标准品,虽然字段情况看着都差不多,但在质量上不是,因为很烂的库也可以说自己是 99.99% 准确,赌的其实是你看不懂。但如果是你和你的团队一行一行的亲自敲进去的,自然会有一些数据的“指纹性”存在的,可以参见当年霍炬的文章官司。就好比拿我们的数据和我们海外的同行做对比,很多时候差异性非常大,抛开数据的对错,起码大家有各自的逻辑和方法在里面,哪怕你直接照着 WHOIS 信息翻译,起码它也是一个方法,但是你去照搬别人翻译好的数据,这就过分了,而且别人弄错了,你也弄错了,这就非常糟糕了,你的底线在哪里?一切向钱看吗? 我当时就陷入了深思和纠结,因为我们从发布商业版本到那个时候,都是毫无保留的制作和提供数据,其实很多朋友都让我们留点心眼,放一些版权信息在里面,以示主权。这个方式,我一直以来都是比较抵触的。但是真的遇到侵权这种事情,好像不这么干,就没有其它办法来核实数据来源了。 通过律师团队建议的可验证的方式,我们有理由认为阿里云发布并对外进行销售的 IP 数据库涉嫌侵权。 说实话,我非常的不爽,也非常的失望,一方面因为本来对这个公司还有一点点的尊敬,毕竟开启了国内云计算的先河,而且也曾经是还是我们的客户,有过合作的非常愉快的时光。一方面是因为大公司做事情难道连几千万的产品市场都不愿意放过都要做了吗?而更大的问题是这是不正当竞争啊。 我们呕心沥血,历时七年八年,最终耗费几十人制作而且要一直这么维护下去的数据,转眼就这么变成了人家手里的产品,要跟你在一个碗里抢饭吃? 而且随着他们销售和推广力度的加大,我们的客户也会经常来找我们说,要么说我们贵了要降价才行,要么说他们更愿意相信他们的数据质量。毕竟人家是大公司嘛,又是所谓的大品牌。我们虽然几十人看着不少,却有何德何能,能和大公司对抗?但是看到这样的话,我心中非常的酸楚,轻描淡写的一句话,就抹杀了你整个团队历时七年八年的努力,好像品牌大就可以解释一切?更何况有些还是多年的老客户,为什么对我们就那么没有信心呢? 问题是在于你数据来路不明啊,虽然产品官网上写了“通过在全球部署大量探测节点,每天定时对 IP 做网络测距分析,找出 IP 地理位置变动情况,确保本产品 IP 查询出的 IP 地理定位信息准确性可靠。”,也写了“借助自身在网络方面的优势,能及时从网络流量上观察到已启用的 IP 信息,能极大的提高 IP 识别广度,确保最新启用的IP地理定位准确,提高 IP 查询结果的可靠性。” 呵呵,难道就这么信任我们提供的数据了吗? 纠结良久,我们选择了采取法律手段进行维权,我们与专业的律师团队签约,半年多的时间里去公证处进行了多次取证,终于在上个月完成了立案手续。 是的,阿里云。那个号称“上云就上阿里云”的那个阿里云。 从发现、取证到起诉,历时接近一年,具体证据就不在这里展示了,让法院认定吧。 这个诉讼的时间周期应该也会比较长,我也会亲自参与这个诉讼的全程,会继续在这里发声,有兴趣的可以保持关注。 我们希望法院可以有一个公正的判决,不要让小公司委屈。也不能让大公司肆无忌惮毫无底线,毕竟还有法律和政府,同样也有人心所向。 现在你明白我们为什么现在会更加封闭了吗?之前无数个例子证明过了,很多大公司来请教、交流,甚至要投资你,看着很坦诚很真实,但其实内心中并不一定是真的这么想的,其实是心里抱着拿你当他升职加薪的垫脚石的阴暗目的,尤其是大公司,总觉得有钱有人,天下我有,就算像素级抄袭,道德如果能约束,还要法律干什么? 我也不知道,根据律师的说辞,这种涉嫌(按照律师的说法,在没有法院判决之前,都只能叫涉嫌)侵权的产品,经过销售之手,卖给客户之后,未来可能会给它的客户带来多大的麻烦?比如那些对合规要求很高,甚至要求供应商必须签署知识产权证明的上市公司乃至是银行、金融行业客户,甚至是政府单位。但这种知识产权证明在签署的时候只能是靠信任和自律。负责销售人员往往要么不知道此事,要么知道也只会关心自己的销售分成有多少。 我相信,要求签署类似知识产权承诺书的公司不止一家,但是我们签署的时候,是有底气的,不知道我们的所有同行在签署的时候,有没有同样的底气呢? 而我们非常委屈的是,在这个等待公证并且立案的期间,基于保密原则,我们并没有跟客户提起这件事情,所以即使我们遇到了客户的疑问甚至是刁难,比如前文说过的要求我们降价甚至是明确说要转买阿里云产品的,都只能绞尽脑汁的想办法想说辞去说服客户留下,商务成本明显变高很多,而知道事实而憋在心里不能直接跟客户讲,你知道我们团队负责面对客户去沟通解释的同事,心里有多难受吗? 同样,我们之前是不太在意同行的数据的情况的,因为自强则万强嘛,即使是客户要求我们做些对比数据,我们也都是应付了事。但因为这个事情,在等待公证的期间,我们下定决心研究了国内外整个行业相对知名的同行的数据。一句老话说的好,害(偷)人之心不可有,防人之心不可无啊。 结果,我们发现中招的可不止一个所谓的“同行”! 而且这个“同行”并不只是涉嫌侵权,其所作所为让我这个自认在这个行业混了好多年的资深人士也算是开了眼,甚至是涉嫌人身攻击,四十多岁再一次经历活久见。 欲知后事如何,敬请关注明天同一时间的下篇文章。 最后,从对行业和知识产权负责的角度,提醒各位看客一下,我们绝大多数的合同里都没有做转授权,如果有公司说他们可以给你 IP 库用,无论是单独的数据,还是集成的数据,无论说是哪家的 IP 数据,尤其是我们的,即使基于合规原则,你也最好要求对方出示授权合同或者授权书,避免涉嫌侵权。如果说是他们维护的,我建议 99.9999% 都不要相信。 原文地址:https://mp.weixin.qq.com/s/fKsHYNrM_ptMlMtLUuurww 转载是为了让更多人看到!

《降临》—— 从外星语言来重新思考“时间”
《降临》(《Arrival》)是根据小说《你一生的故事》(《Stories Of Your Life And Others》)改编的,由艾米·亚当斯和杰瑞米·雷纳主演的一部关于外星人“降临”地球的电影。 从想了解外星人“你们是谁?”,“从哪里来?”,“要干什么?”带入主题,找到影片主角路易斯——语言学家来与外星人沟通展开,以及后续发展的故事。 剧照 语言改变人的思维 整部电影都是基于这个“语言能改变人的思维模式”来进行的,不管这个理论正确与否,都要带着这个观点去看,不然很多地方会有困惑。 该片就是围绕主角路易斯学会外星人七肢桶的语言——七文展开,获得了一些“超能力”并挽救一些的故事。 影片下载 磁力链:magnet:?xt=urn:btih:bff39b3a9d68e2a180922e9124752c437d6b5685&dn=Arrival.2016.1080p.BluRay.x264-SPARKS&tr=http%3A%2F%2Ftracker.trackerfix.com%3A80%2Fannounce&tr=udp%3A%2F%2F9.rarbg.me%3A2710&tr=udp%3A%2F%2F9.rarbg.to%3A2710 个人推荐 这部电影虽是近几年来比较新的电影,可我上篇文章就说到过,我从高中开始就很少看科幻片,所以也就没有看。我是在ClubHouse听别人聊天时被安利的,确实是近几年来比较好的科幻电影,看完之后也有些许感悟,里面一些观念真的可以让你重新思考时间和未来。 同时推荐看原著《你一生的故事》(《Stories Of Your Life And Others》),里面描述主角女儿的片段真的超级优美。 其实我一直都在想如果人生来继承的上辈的知识结晶,一方面来说,作为碳基生命而非硅基生命,获得了几万年来总结的知识得以继续传承下去;另一方面,某些固化的思维模式可能限制了人类往更高层次的发展。 正如原著提到的,在七肢桶的世界观,可能人类的千古难题对于他们来说,只是常理而已。 最后提出一个问题,感兴趣的小伙伴可以在评论区留下你的想法。 如果你知道你的未来,且无法改变,你是选择按部就班的一步步过完无聊的人生还是选择自杀? 同时,对于这个问题,想要深究的,可以看《西西弗神话》——阿尔贝·加缪。从哲学角度来讨论这个问题

Potplayer无广告版本/官方旧版本
Potplayer作为一款windows下功能强大的免费播放器,终于在去年的更新中加入了广告模块。虽说这是免费软件的盈利方式,可博主用惯了无广告的纯净版本,突然给我升级说有广告,就有点强迫症。 PS:这里还是鼓励大家能忍受广告的,想支持这么好的软件的,可以顺其自然让他展示广告,毕竟别人也要盈利的嘛。 Potplayer无广告版本下载 根据网友消息,potplayer是在1.7.18958版本 废话不多说,直接放下载链接。非32位用户请不要下载32位,这里大部分人电脑应该都是64位,下载第一行的64位安装程序即可。 PS:由于是旧版本,需要配合文末的屏蔽更新的法子来永远停留到当前版本。 Potplayer官网下载 官网最新版,即有广告版本下载。(供爱心人士下载给开发者提供广告收益) Potplayer屏蔽更新 由于更新是联网检测,Windows用户如果使用电脑管家或者其他管家软件,应该可以直接将应用程序禁网来达到禁止更新的效果。 但以上方法不太优雅也不太方便(我常用potplayer播放需要联网的内容),所以在这里我个人使用的是host屏蔽的方法,将检测更新的网址给屏蔽掉来达到禁止更新的效果。 打开hosts文件,在末尾加入屏蔽更新的host,保存即可。 hosts地址:c:/windows/system32/drivers/etc/hosts Potplayer屏蔽广告 对于1.7.18958以上版本,或者不想使用旧版本的用户,可以使用Reddit用户公布的方式来屏蔽广告。 原地址:https://www.reddit.com/r/potplayer/comments/gu25jc/archive_of_olderprevious_versions_of_potplayer/ftc4aa7/ 与禁止更新的方法一样,也是通过修改hosts来屏蔽广告。这里直接放代码,具体操作方式见上一段落。
ntfs硬盘无损转Ext4——记一次骚操作
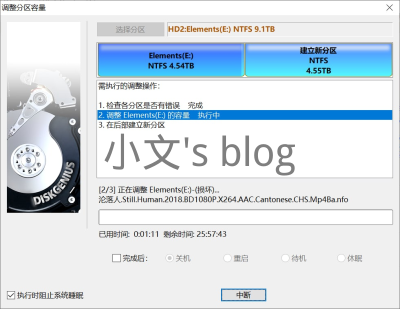
前年买了一块Wd Elements 10T便携移动硬盘,由于当时是买来插Windows上,切该硬盘出场格式是NTFS,自然直接插上就能用了。但是最近我把它插到树莓派(Raspbian)上时,每次读取写入的速度都特别慢,更有甚者,连qBittorrent直接罢工,无法写入到硬盘。后来htop查看进程才知道有个ntfs-3g的进程,在读写时几乎占用了100%cpu(一核心)。 查资料得知,Linux系统在读取ntfs格式硬盘时,会调用ntfs-3g程序去实时转换。由于树莓派cpu性能一般,所以导致读写超级慢(20m/s)。于是便有了想将手头的影片转成Linux支持的ext4格式的想法。由于硬盘过大,里面的数据也太多,刚好遇上挖矿热,买不到比较便宜的硬盘,所以才有了这篇文章的骚操作。之所以称之为“骚操作”,是因为此篇文章所涉及到的无损转格式的方式虽说是某知名网站推荐的方式,但对于数据安全极不友好,不建议不了解硬盘、Linux系统相关知识的小白尝试。 如果你实在有需求要按照本文操作来转格式的话,由停电,电脑死机等一系列问题导致的数据丢失,本人概不负责! 主要流程 由于整个过程实在耗费时间和资源,这里先讲讲主要流程,在每个板块都会写出详细步骤,以及遇到的问题和解决方法。 Linux下停止正在使用该磁盘的进程,卸载磁盘 磁盘压缩主分区ntfs(分区N1),格式化出一个Ext4分区(分区E1) 将主分区的文件尽可能多的移动到Ext4分区,知道Ext4分区塞满 如果主分区还有文件,则重复2-3步骤,直到主分区文件全部被移动到新的分区。 格式化主分区为Ext4(N1),将临近主分区、存有数据的Ext4分区(E1)里面的全部数据移到主分区。 删除Ext4分区(E1),并将删除腾出来的空间去扩容主分区(N1) 如果之前有创建多个Ext4分区的话,重复5-6步骤,直到整个硬盘只剩一个Ext4分区即完工! 强烈建议数据在1/2磁盘空间以下,比如我10T硬盘4.7T数据,这样就可以只用分出一个区来保存数据就行,省了很多步骤。 卸载硬盘 为避免出现数据被更改的问题,先停止正在使用该硬盘的进程,然后使用umount命令卸载硬盘才进行数据转移的操作。 如上,如果使用umount卸载时出现“target is busy”,则说明该磁盘正在被进程占用,我们使用lsof查看占用的进程,将其关掉再卸载即可。 压缩分区(6h) 由于数据是散乱存放(非连续)在硬盘上的,所以导致我是用Windows磁盘管理工具去压缩卷的时候,本应该有5T空间剩余,磁盘管理工具却只能压缩出500G左右空间。 所以我使用DiskGenius工具,它应该是帮忙整理磁盘的内容尽量靠前且连续,然后再压缩卷。我这里使用DiskGenius可以压缩出4.55TB,耗时大概6小时。 压缩完成后,将新分区格式化为Ext4格式即可。Windows下无法识别,可以用DiskGenius软件看到新的分区。 数据转移(10h+23h) 考虑到稳定性,我原本打算用DiskGenius在windows下将ntfs分区的数据转移到ext4分区的,可这货居然提醒我 “该功能是Pro用户才能使用”,便转换思路,使用双系统的Ubuntu去操作转移。后来想想,Ubuntu远程操作也方便,应该为首选方案的,最后,我还是将硬盘插上我的Ubuntu,然后使用使用命令行在tmux下进行mv操作。操作完我就去上班了。 好景不长,等我回到家时,想查查进度的我却发现硬盘没了!然后键盘也失灵。仔细想想,既然硬盘已不存在挂载中,键盘也失灵,那我本着重启能解决99%问题的心态重启Ubuntu(对,就这么严谨...)。重启后,系统正常使用,然后查看日志,便发现HC died报错。 果然不是我一人,万能的网友也有遇到这个问题的,也给出了详细解决方案。 https://zhuanlan.zhihu.com/p/158688481 于是我重新运行mv命令去转移数据,由于之前已经转移过部分数据,所以只需要转移未转移的部分即可。 最后终于转移完成(我已经将ntfs分区格式化为Ext4了,第一个卷) 最后将清空的ntfs分区(N1)格式化为Ext4即可。 最后的数据转移(30h) 由于分区无法向前合并,我这里还是将tmp分区的内容全部转移到Elements分区。 考虑到复制任务占用电脑,便把硬盘插到树莓派上进行mv操作。(由于我的硬盘是外部供电,也不用担心供电不足或者其他问题) 此番很顺利,没有出现Ubuntu的HC died的报错,花费30小时终于将所有内容转移到第一个Ext4分区了。 分区合并(15mins) 首先卸载分区。然后使用fdisk进行分区合并的操作。 使用Linux下的fdisk命令操作。内容有点多,由于没有截图,这里不详细展开。 流程:删除第二个分区(9999999-66666666),再删除第一个分区(2048-9999999),最后新建一个分区(2048-66666666)即可。 注意:新建分区的时候,如果显示“已检测到文件系统,是否清空?”的提示,千万选择否,不然数据可能被清空。 最后,使用fdisk检查你的硬盘编号,再使用e2fsck来执行磁盘检测。最后使用resize2fs命令来扩容区分1即可。 至此,本文的ntfs无损转Ext4已完成,最后只需使用mount挂载在树莓派系统即可。 后记 本次是本人的作死之旅,望不要盲目跟从,数据无价,在对硬盘进行任何操作时,请提前备份。 由于读写“同时”进行,所以数据转移过程极慢,我这边WD Elements 10T硬盘拷贝5T大概30h,瞬时读写速度大概50m/s,该数据仅供参考。 如果你是和本人一样不怕丢失数据,手头有没有多的硬盘,并且ntfs格式的硬盘实在用不下去了,你可以跟着本文的操作去走,但是如出现数据丢失,本人概不负责。 最后,放几张图吧。 Windows SMB本地挂载 fdisk磁盘信息 读写速度测试 参考 https://recoverit.wondershare.com/partition-management/ntfs-to-ext4-easily.html#part3
为宝塔面板升级Python3
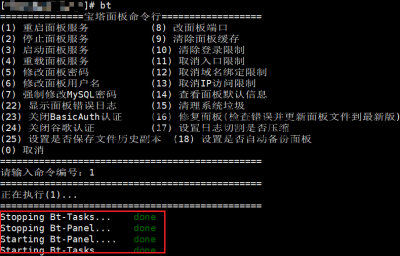
python官方早在前年就宣布将于2020年不在维护python2,建议广大使用者将其更新至python3,今天查看宝塔后台状况,却发现好几台老旧的服务器都是使用的python2,查了下相关资料,官方也宣称支持python3,于是我便开始了我的升级之旅。 安装python3 新版本系统是默认自带python3的,查看是否支持python3可以使用python3命令。 返回正确的python版本则说明已经安装了python3,反之亦然。 apt安装(ubuntu debian...): yum安装(Centos, Rhel...): 安装依赖 安装完python3之后,默认会安装python包管理器pip。由于之前系统默认的pip为python2的包管理器,所以我们使用pip3命令来安装依赖即可。 无报错安装完成即可。 更改为默认的python版本 输入以上命令可以看到,当前python版本为python2,所以我们要将默认的python2改为python3。 删除python快捷方式,重新绑定python3到python即可,命令如下: 还有默认的包管理器pip也更改为pip3 重启面板 输入bt,按照命令行提示输入1(对应重启面板),无报错即为更换成功。 再次进入面板,可以看到已经更换为python3,至此大功告成。 遇到的坑 yum无法使用 更换默认的python到python3之后,Centos yum命令无法使用。 这是因为yum默认使用python2版本,所以我们要更改yum的python代码为python2 用vi编辑器将第一行改为python2然后退出保存即可
emby使用技巧与进阶
近期爆火的《正义联盟》镇楼。上文说到emby的安装就没有继续进行下去了,是因为篇幅有限,emby的安装和使用以及一些小技巧很难全部在一篇文章里详细讲完,为了逻辑通顺以及排版正确,我这里另开一篇来讲讲emby的控制面板的使用以及我在使用过程中遇到的痛点以及我是如何解决的。 emby控制面板——添加媒体库 如果你是按照上文的教程一直走到尾,那么你仅仅是安装了emby,更重要的内容没有填充进去,所以首当其冲的,我们要设置媒体库将我们硬盘里的电影展示出来。 如上GIF所示,添加媒体库就是将你磁盘的电影目录告知emby,让他去扫描电影信息。最后回到首页,就能看到emby扫描出来的电影。如下图: emby控制面板——更正错误的识别信息 由于emby是根据文件名称去影库搜索对应的电影,然后在匹配,难免会有匹配错误的问题,这时我们就要手动更正识别错误的影片。 如上图所示,由于英文名恰巧和别的电影一样,导致匹配错误。 我们右键点击识别,然后输入名称双瞳,再将搜索出来的结果替换即可。 如果有名称搜索不到的情况,则可以选择填写IMDb或者TheMovieDb的id去识别,这样识别出来的准确率几乎是100% 格式如下: 例如双瞳的IMDb链接是:https://www.imdb.com/title/tt0284066/ 那么你需要填写的id就是tt0284066 同理The MovieDb链接是:https://www.themoviedb.org/movie/57100-shuang-tong 那么你需要填写的id是57100-shuang-tong 国内推荐使用TheMovieDb去识别,对中文名称电影更友好。 emby控制面板——字幕下载设置 在添加媒体的时候你可能就已经注意到了,媒体库会让你选择你的国家和语言以及首选下载字幕语言,如果你有勾选对应语言,他是会自动帮你下载字幕到电影那里,这样你在播放的时候就能选择字幕。 这里建议大家勾选Open Subtitle,我实际使用下来发现OpenSubtitle的字幕还是挺全的,部分冷门可能只有英文,如果你英文不太好的话可能要用工具机翻该字幕(后文emby字幕进阶——中英翻译会讲到)。 Open Subtitle设置也很简单,只需要你去Open Subtitle注册一个账号,然后在仪表板的Open Subtitle设置里填写账密即可。 然后你在电影界面就可以自由选择字幕。 如果没有设置自动下载字幕或者没有自己想要的字幕,也可以手动从Open Subtitle下载 点击更多,修改字幕,然后选择自己想要的字幕,搜索然后下载即可。(刚好遇到opensubtitle维护,这里就不演示了) emby字幕进阶——字幕命名规则 emby有一套很严格的命名规则,如果你不按照规则来,他是无法识别的。具体规则参考emby官方文档 首先,最重要的一点就是,字幕类型和字幕名称。一定要保证字幕名称(除去后缀)和电影名称相同。 比如电影文件Voice.of.a.Murderer.2007.KOREAN.1080p.NF.WEB-DL.DD+5.1.H.264-ARiN.mkv 有效的中文字幕如:Voice.of.a.Murderer.2007.KOREAN.1080p.NF.WEB-DL.DD+5.1.H.264-ARiN.zh.ass 即保证主体部分一字不差的相同 emby支持的字幕 ass srt ssa sub/idx vtt ebmy支持的语言 https://www.loc.gov/standards/iso639-2/php/code_list.php emby支持的扩展 强制字幕 forced/foreign 默认字幕 default 几个例子 电影名:Voice.of.a.Murderer.2007.KOREAN.1080p.NF.WEB-DL.DD+5.1.H.264-ARiN.mkv 中文字幕:Voice.of.a.Murderer.2007.KOREAN.1080p.NF.WEB-DL.DD+5.1.H.264-ARiN.zh.ass 英文字母:Voice.of.a.Murderer.2007.KOREAN.1080p.NF.WEB-DL.DD+5.1.H.264-ARiN.en.ass 默认使用中文字幕:Voice.of.a.Murderer.2007.KOREAN.1080p.NF.WEB-DL.DD+5.1.H.264-ARiN.zh.default.ass 强制/外部字幕:Voice.of.a.Murderer.2007.KOREAN.1080p.NF.WEB-DL.DD+5.1.H.264-ARiN.zh.forced.ass emby字幕进阶——自定义字幕 网上的电影版本太多,字幕版本也不计其数,所以就导致你下载的字幕可能和电影时间轴对不上,这时就需要你手动使用工具去调整字幕文件时间轴或者将其翻译成你想要的语言。 我使用的工具是Subtitle Edit,这是一款开源的字幕编辑工具,基本能满足我的日常字幕需求。以下的字幕编辑操作均以该软件为工具进行操作。 下载地址:https://github.com/SubtitleEdit/subtitleedit/releases/download/3.6.0/SubtitleEdit-3.6.0-Setup.zip 字幕调时 字幕翻译 我是如何使用emby的 资源下载 Aria2+Tele-aria2(Telegram机器人下载磁力链) 教程参考:https://p3terx.com/archives/aria2-telegram-bot-automatically-uploads-to-google-drive-onedrive.html Transmission docker安装即可 字幕工具 subtitle edit(字幕时间轴编辑、翻译) github地址:https://github.com/SubtitleEdit/subtitleedit subRename(字幕文件名称整理) github地址:https://github.com/arition/SubRenamer renamer(字幕文件名称整理) 官方网站:https://www.den4b.com/products/renamer iOS客户端 emby 付费软件,30人民币永久使用,可以多设备(同一个ID)共享,还是很划算的。 中英字幕下载网站 字幕库:http://zimuku.la/

树莓派docker环境安装
docker安装 树莓派默认是没有安装docker的,而docker的安装也异常简单,只需使用apt安装即可 而由于国内环境问题,apt下载网速慢的同学可以替换清华镜像,https://mirrors.tuna.tsinghua.edu.cn/help/raspbian/ 执行完以上脚本等待安装完成即可! 安装完成后执行docker version看看是否安装成功 dokcer-compose安装 docker-compose也和docker安装一样,apt安装即可。 如apt无法安装 可以使用pip安装,但pip安装的docke-compose可能存在需要配置环境变量的问题,下文会说到 安装完成后执行docker-compose version看看是否安装成功 docker-compose 环境变量 安装完docke-compose后,为了能在全局使用docker-compose命令工具,我们要将docker-compose安装目录添加到系统环境变量。 我的安装目录是/home/pi/.local/bin/docker-compose 所以我在~/.profile文件添加这样一行代码

利用树莓派自建私人媒体库-Emby
前言 我觉得我小舅说的蛮有道理的 他说:电影发明以后,人类的生命比起以前至少延长了三倍! 《一一》 我一直都是一个电影迷,从高中开始看科幻片,大学开始看悬疑片,一直到现在,除了一些狗血爱情片,我基本都看。文章末尾会放出我搭建的emby私人影库,大家也可以看看我的口味,哈哈。 自从大学开始所看的电影我就一直保存在硬盘里,当然那时候的硬件设备都不太好,移动硬盘也只有2T空间,所以我下载的都是一些720p的内嵌字幕的电影。也不知道是为了什么,像是和那些把所有抓来的娃娃放柜子里展示的小姑娘一样吧,我喜欢把看过的电影陈列起来。当时没有技术,只是简单的将电影按照年分类保存。 慢慢我硬盘换了4T,换了10T,这些大学保存的电影从一个盘拷到另一个盘,好在是没有遗失。之前想过用软件来建立一个已看清单,我用了iOS的一个叫做Mark的软件,花了几天时间将脑子里能想到的电影全部保存,然后每每看完电影就去Mark评分,它会自动加到已看清单。 直到前几日,我在Telegram接触到有这种私人影库,能通过识别电影文件名来刮削电影信息并保存,以此来达到私人影库的实现。刚好我手上有一个正在吃灰的树莓派,我便开始着手去研究搭建一个属于自己的私人影库,不是为了给别人看,光是看到自己所有的电影电视剧全部整齐的摆放在那里就已经很心满意足了! 废话一大堆,正片正式开始咯! 准备工作 我是Raspiberry 4B + 4T +10T移动硬盘 我树莓派用的32位的raspio最新版本 2021-01-11-raspios-buster-armhf-full.img 下载地址:https://downloads.raspberrypi.org/raspios_armhf_latest 不建议使用64位,性能是有提升,但是目前好像有很多坑。同时,如果你是使用64位系统,本篇教程可能不适合你。 此篇文章由于篇幅问题,无法做到能让完全不熟悉Linux系统命令的同学食用,如果你不熟悉Linux系统,建议寻求其他更详细的教程 准备工作 树莓派Docker环境安装 树莓派mount自动挂载硬盘 Linux系统mount自动挂载 按照说明编辑/etc/fstab文件即可 https://wiki.archlinux.org/index.php/Fstab_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87) 官方Docker地址 https://hub.docker.com/r/emby/embyserver 支持以下的架构,本文树莓派4B arm32v7使用的是emby/embyserver_arm32v7 文中更详细的安装以及参数配置说明 可以参考 开始搭建 目录创建 emby只需要一个config目录,用于保存配置信息以及影片缓存。官方建议50G以上。这里建议将config目录创建于你挂载的移动硬盘目录即可。(例如我的:/mnt/sdb/emby/config) 在你挂载的目录新建一个emby文件夹,用于存放docker-compose.yml文件和config目录 创建docker-compose文件 在emby文件夹新建一个config目录 然后用vim新建一个docker-compose.yml文件,复制好官方提供的docker-compose配置文件后,按需修改部分配置即可。 我的配置如下: 由于vim编辑yml文件时,粘贴的代码会自动缩进,这里建议先vim docker-compose.txt,复制进docker-compose.txt文件,保存后重命名该文件然后再编辑。mv docker-compose.txt docker-compose.yml 启动Emby 在当前目录(/mnt/emby)下,执行 即可看到docker拉取镜像,等操作,等待其完成即可。 检查成果 embyserver开启之后,你便可以在浏览器输入对应的网址和端口进行访问,配置你的私人影库啦。 比如我的树莓派内网地址是:192.168.50.121 那么emby地址就是192.168.50.121:8096 刚开始可能embyserver没开启起来,等待十几秒之后浏览器访问该网址应该可以看到emby安装引导界面,然后按提示操作即可。

安卓手机短信转发Telegram
前言 由于手机卡太多,早就本准备买GSM模块配合树莓派做一个短信收发平台,换了新手机之后旧手机就闲置下来,本着废物利用的心态在网上搜了下相关解决方案,在先后尝试了IFTTT、Tasker之后,在V2找到了V友强烈推荐的开源app,也是本文的主角:Telegram-SMS。 成品图 用了几天,我觉得基本是我目前使用过的方案中最完美、优雅的解决方式了。 PS:由于本人手机无ROOT权限,之前没用过Tasker等工具且目前只需要这一个短信转发的单一功能,所以我觉得这是最适合我的App。 如果你手机已经有If this then that类似软件,那么你只需添加一条规则即可。 Telegram控制备用机发送短信 接收短信 Telegram-SMS 项目地址 https://github.com/telegram-sms/telegram-sms 使用说明 https://guide.telegram-sms.com/zh_cn/user-manual.html 下载地址 免费开源版本:https://github.com/telegram-sms/telegram-sms/releases/latest 商店版本(付费):https://labs.xda-developers.com/store/app/com.qwe7002.telegram_sms 使用方法 准备工作 肉身国外 或者 国内+Socks5代理 闲置安卓机一台(24h联网状态) Telegram账号 1. 创建Telegram机器人 在Telegram App搜索botfather,发送/start开始创建机器人,然后按照提示操作即可。创建成功后保存好机器人Token,后续操作会用到。 点击上面消息中的蓝色链接,进入到你的机器人聊天页面,给你的机器人随便发条消息。 2. 下载Telegram-SMS 打开Github链接,直接下载安装包即可。 https://github.com/telegram-sms/telegram-sms/releases/latest 安装成功之后,直接在设置里打开该软件的所有权限,如果是按需开启的话,可能你手机不在身边会有收不到短信的问题。 3. 编辑配置 打开网站https://qrcode.telegram-sms.com/,填写相关信息后生成配置二维码便于手机获取配置。 填写创建机器人成功后的token 给你的机器人发送消息后,点击GET RECENT CHAT ID按钮,即可获取到你的聊天ID 填写你的常用手机号,便于网络不好时转发短信到该手机号 5个按钮全部打开 点击GENERATE QR CODE生成二维码 打开手机App,点击右上角扫描按钮,扫描即可自动填写配置到APP APP保存配置 打开app,点击右上角扫描按钮,即可自动填写配置文件。勾选想要开启的功能,点击测试并且保存即可。如果Telegram收到机器人的消息,则说明开启成功。 成功开启后保持软件后台运行即可。 如本地网络不佳需设置代理,点击右上角设置按钮,找到代理设置,填写你的代理地址即可。 功能测试 短信测试: 打开爱奇艺,切换到手机验证码登录,测试即可 发送短信测试: 在Telegram给机器人发送/sendsms1指令,然后填写收件人和信息,等待测试即可。 注意事项 收到短信无反应 这个问题通常发生在经过深度定制的手机系统上,通常由于安全问题,拦截了所有的短信广播。这个问题目前的解决方案是将 Telegram SMS 配置为默认短信应用,或者通过监听推送通知的方法来获取短信内容。 telegram发送指令无响应 查看app日志,如果有Connect Failed类似字眼,说明网络环境不稳定或者无法连通到Telegram导致消息发送失败。解决方法是更换稳定的网络和代理。 更多Q&A 官方Q&Ahttps://guide.telegram-sms.com/zh_cn/Q&A.html 如果在使用过程中遇到任何问题,可以在文章下方评论,我看到会第一时间解答并整理到文章中给大家排坑。