
起因是有个同样功能的机器人,我用来传些电子书,但是用了几次就显示要收费才能使用,贫穷的我哪能受得了这委屈,刚好手边有发件服务器和域名,正好自己造个轮子。 Kindle为了方便用户传送文档,是可以直接通过电子邮件接收文件的。使用这个机器人,我们就可以随时随地发送个人文档到kindle,而kindle只需要联网,就能自动下载我们通过机器人发送的文档。 项目地址 https://github.com/qcgzxw/ebook-sender-bot 欢迎Star!欢迎PR! 项目部署文档可在readme查看,程序语言是python,其中书籍转换的功能用到了calibre。 如果想部署该项目,必须具备如下环境: 可用于访问telegram的网络 python3环境 SMTP发件服务器 calibre环境 使用方式 首次使用需要设置邮箱,以后使用直接传文件即可,不再需要额外的设置。 telegram搜索e_book_send_bot,或者浏览器打开https://t.me/e_book_send_bot,打开机器人 按START按钮,机器人会发你详细操作。 接着发送 /email 你的kindle邮箱@kindle.cn 绑定你的kindle邮箱 如果邮箱格式正确,则会返回提示信息绑定成功,然后去kindle将机器人的邮箱添加到白名单 添加完成后,发送文档给机器人,随后在kindle首页刷新看是否有新文档即可。 搭配1library免费看书 细心的小伙伴可能已经发现了,上图演示的文件是从1library机器人转发来的,本人也是使用该机器人来转发电子书到kindle,书库很大基本没有找不到的资源。 Z-Library是号称全球最大的电子书库,经我本人几个月的测试,确实我想要看的书都有,甚至网络小说都有人制作好了上传在上面。 对于免费账户,每天限制下载5本书,且下载速度被限制到1MBps。虽然付费之后可以直接在网页端和tg机器人转发给kindle,但是贫穷限制了我的想象力,只好自己写个机器人来曲线救国。 这样我们只需多花1秒钟的时间,将书籍文件从1lib机器人转发给我这个机器人,便能白嫖会员功能。 操作 telegram搜索firstlibrarybot,或者浏览器打开https://t.me/firstlibrarybot,打开机器人 点击start之后,会发出一个链接绑定你的账号,打开链接,去官网注册一个账号登录 登录之后在编辑个人信息最下面有个绑定telegram机器人,是个链接,点击选择telegram打开就绑定完成了 最后可以直接在机器人发送书籍名称来搜书,然后转发给我的机器人即可推送到kindle

记录使用PyInstaller打包exe可执行程序遇到的问题
pyinstaller安装 官方网站:https://www.pyinstaller.org/ 直接使用pip安装即可全局使用。 本文仅记录博主在pyinstaller使用过程中遇到的一些问题,如果你是第一次接触pyinstaller,请先阅读pyinstaller说明文档 pyinstaller常用参数 部分常用命令行参数如下: 通常,由于参数过多,不方便记录,博主一般先生成.spec文件后再编辑spec文件。 PS:spec文件是pyinstaller打包过程中生成的配置文件,所有的命令行参数都会存于该文件。 使用pyi-makespec来生成spec文件 参数和pyinstaller一致,执行完毕后会在当前目录生成一个.spec的配置文件,部分参数和说明如图: 修改完spec文件之后,用pyinstaller打包即可在dist文件夹内生成可执行exe pyinstall打包单个py文件 pyinstaller 引入资源文件 如果是简单的脚本,通知只需要一个main.py程序即可完成,我们只需要打包单个py文件即可。 可如果涉及到资源文件的引入(比如外部调用文件),我们就需要将这些文件一起打包进exe文件里,方便调用。 将多个杂乱无章的文件转换成一个可执行文件,这也是打包的意义所在。 首先我们要在spec配置文件中配置要引入的文件夹 打包的可执行程序在运行过程中,会将这些目录释放到系统的tmp临时目录,我们要适当修改程序来获取这些目录的绝对地址供我们在程序中调用。 pyinstaller -w(--noconsole)参数导致无法运行 根据官方文档,打包时加入-w参数不弹出控制台。 我当然是默认就加上了,可在实际测试过程中发现,程序一闪而过,没有输入输出,最后还是去掉了w参数。 如果脚本使用文件输入输出函数的,建议去掉这个参数。 Windows7执行报错 缺少api-ms-win-core-path-l1-1-0.dll 由于最新的python3.9不支持Windows7,所以导致使用python3.9打包的可执行程序不能再Windows7上运行。 使用Windows3.8打包或者在打包时引入api-ms-win-core-path-l1-1-0.dll文件即可。 引用: 详细的打包流程:https://yujunjiex.gitee.io/2018/10/18/PyInstaller打包详解/ spec文件说明:https://pyinstaller.readthedocs.io/en/stable/spec-files.html 本文项目:https://github.com/qcgzxw/pdf2image
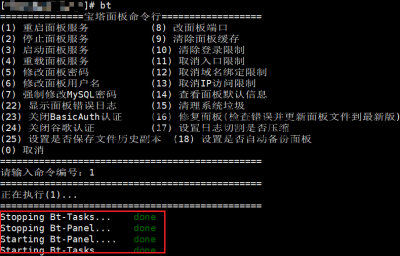
为宝塔面板升级Python3
python官方早在前年就宣布将于2020年不在维护python2,建议广大使用者将其更新至python3,今天查看宝塔后台状况,却发现好几台老旧的服务器都是使用的python2,查了下相关资料,官方也宣称支持python3,于是我便开始了我的升级之旅。 安装python3 新版本系统是默认自带python3的,查看是否支持python3可以使用python3命令。 返回正确的python版本则说明已经安装了python3,反之亦然。 apt安装(ubuntu debian...): yum安装(Centos, Rhel...): 安装依赖 安装完python3之后,默认会安装python包管理器pip。由于之前系统默认的pip为python2的包管理器,所以我们使用pip3命令来安装依赖即可。 无报错安装完成即可。 更改为默认的python版本 输入以上命令可以看到,当前python版本为python2,所以我们要将默认的python2改为python3。 删除python快捷方式,重新绑定python3到python即可,命令如下: 还有默认的包管理器pip也更改为pip3 重启面板 输入bt,按照命令行提示输入1(对应重启面板),无报错即为更换成功。 再次进入面板,可以看到已经更换为python3,至此大功告成。 遇到的坑 yum无法使用 更换默认的python到python3之后,Centos yum命令无法使用。 这是因为yum默认使用python2版本,所以我们要更改yum的python代码为python2 用vi编辑器将第一行改为python2然后退出保存即可

吃灰Kindle复活计——用Kindle看网络小说
曾经连续几个月关注它就为了等它降价几十块,还没买回来就已经幻想好日日夜夜与它形影不离,当它真的闯入你的生活,你不禁感叹:真香!(用Kindle盖出来的泡面真香) 甚至官方都开始自嘲用kindle盖过的泡面会更香,你的Kindle还好吗?还是说你已经一边用电脑看书一边用Kindle盖泡面了? 思路梳理 本文不会通过介绍热门书籍的方式让你重新拿起Kindle,而是教你如何将自己喜欢的网络小说放进你的Kindle。 PS:本文涉及专业性知识较多,如过你并没有接触过Python和爬虫,请直接在评论区留言小说名,我有时间会帮你制书。 在小说网站找到你喜欢的网络小说,使用Python爬虫爬取每一章小说的内容 将爬取到的内容按章节区分,使用csv格式保存并排序 python读取csv文件并按照制书软件要求的格式将其装化成txt文件 使用制书软件将txt文件制成mobi格式的电子书 将书籍导入Kindle(邮箱推送或者连电脑通过usb传输) 书籍抓取 本节涉及到技术:Python, Scrapy 现在网上各类小说网站层出不穷,我们要做的就是在这些小说网站中找到想看的书籍并保存到本地。 确定网站 1、网站路由:每一章页面url最好是https://[域名]/[小说标识]/[章节标识].html,便于抓取;章节标识最好是有序数字(可以不连续),便于章节排序。 2、防爬虫机制:最好找那些没有防爬虫机制的网站,会大大加快我们爬取速度。 本站使用的示例网站是:m.biqudao.com 工具安装 python环境下,使用安装scrapy库,然后使用scrapy命令创建和编写爬虫。 [crayon-680bd04950786845894601/] 如果遇到安装错误,可能是要手动下载安装Twisted依赖。 开始爬取 我写的爬虫文件如下,可供参考。爬取速度大概1秒10章 https://github.com/qcgzxw/scrapy [crayon-680bd0495078c841741840/] 输出为csv文件,便于章节排序。 爬出来的文件时乱序 章节排序 将输出的csv文件用Excel打开,按网址排序即可。(如果内容过多,打开和排序可能会卡顿) Excel打开乱码解决方式:使用Notpad++软件打开csv文件,点击 ,,保存后再次用Excel打开即可。 转txt文件 我使用的制书软件是calibre - E-book management,他要求的格式是用##来表示章名,所以我们从csv文件中读取并转化成对应格式的txt文件。 https://github.com/qcgzxw/scrapy/blob/master/csv2txt.py 运行该脚本即可转化成txt文本。 书籍制作 下载安装配置calibre - E-book management软件,将转换好的txt文件拉进去,然后选中,点击转换书籍。 不需要过多操作,点击确定即可开始任务 等半小时就好了,直接右键点击转换好的mobi格式的书籍,点击共享,发送邮件至***,kindle联网即可自动获取到通过邮件发送的文件了。 PS:转换过程很慢,我一本20M的书花了2小时。 效果展示
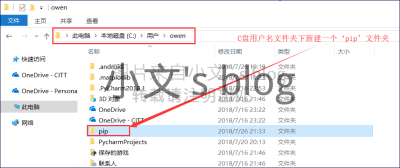
《Python疑难杂症》——(一)PIP安装模块下载慢或者无法下载
前言 正式入坑Python,遇到的几点疑难杂症和搜索到的解决方案在这里给大家分享下。希望能帮到一些初学者,你也可以在文章下面评论你遇到的Python问题以及解决方案,为那些初学者不至于半途放弃学习Pyhton。后期有机会的话,会将《Python疑难杂症》这一系列整理到一起,打包成文档或者单独的专栏。 Chapter 01——pip下载不动,模块安装失败 由于pip默认的下载源在国外,下载的人也多,难免有时会抽风,下载慢还能熬一熬,有时候就直接安装失败了。 解决方案如下: 通过添加配置文件永久更换pip安装源至国内镜像 [crayon-680bd04950b31471527453/] 在C:\Users\owen\下新建一个pip文件夹 在pip文件夹里面创建如下pip.ini文件,用于保存pip安装源地址 [crayon-680bd04950b35958571109/] 文件保存好后,再来到cmd,输入pip install xxx的时候,你就会发现,无论安装什么模块,都是秒下载。 通过下载wheel文件手动安装 推荐一个比较好的python模块下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/ 打开后,想要下载什么模块,就按住Ctrl+F搜索对于的模块名,然后点击下载wheels文件。 下载后,打开cmd窗口,进入到该文件的目录,然后执行pip install 文件名即可安装成功。

用Python画一个中国地图【转】
为什么是Python 先来聊聊为什么做数据分析一定要用 Python 或 R 语言。编程语言这么多种, Java , PHP 都很成熟,但是为什么在最近热火的数据分析领域,很多人选择用 Python 语言? 数据分析只是一个需求,理论上来讲,任何语言都可以满足任何需求,只是麻烦与简易之别。 Python 这门语言诞生也相当之早,它的第一个版本是 26 年前发表的,曾经(或者说当前)也被用于web开发,但是就流行程度来说,远远干不过 Java 和 PHP 。东方不亮西方亮,在与 Java 干仗失败的这20几年时光里, Python 练就了一身独门武艺,是 Java 和 PHP 远远不及的(当然以后是不是能追得上来,目前还不好说)。你要说做个博客网站, Python 的特长不在这里, PHP 和 Java 也是分分钟的事情。你要说做个 BBS 网站,做个电商网站, PHP 手到擒来。 Python 在这些方面和 Java 或者 PHP 竞争,基本就是作死的节奏,虽然也有 django 这样的框架,但流行程度远远不及其他语言。但在这些年默默的失败背后,有一帮研究人员用 Python 干出了一些惊天地泣鬼神的神器,使 Python 在数据研究领域做到了除了 R 语言以外基本无人能及的地步。 Jupyter 首先,第一神器是 Jupyter 。如果你是第一次使用,可能搞不清楚它的开发者做这么个鬼东西出来干什么,说它是博客系统也不像,说它是web服务器也不像,但它就是有用。因为我们传统的web开发首先想的就是面向公众,你做一个服务器就是要服务成千上万浏览器的,当然 Jupyter 也可以服务众多浏览器,但它更多的还是方便研究人员,对研究人员来说简直是太方便了,你把代码像写文章一样直接写在输入框里,然后在本页面直接就看到了这个代码的结果,随时修改,随时展现,文码混排,是 Markdown 的一个增强版,毕竟 Markdown 还只能显示文字,最多再加上一些图片,而 Jupyter 是可以直接运行 Python 代码的。当然,也有些人试图在 Jupyter 里运行 PHP 或 Java 代码,但显然成不了气候。 因为 Python 这个语言天生就是脚本语言,可能将来唯一有希望往里移植的就是 Javascript ,这货也是一个脚本语言。脚本语言的好处就是不用编译,一行一个结果。纵观计算机语言发展历史,就是一个从繁到简的过程,C语言需要编译+链接才能运行, Java 只要 javac 一下,把编译和链接合二为一, PHP 更简单,直接运行就行了,连编译都省了。但是还不够直接,因为还要编写一个 .php 文件存盘,然后才能运行,到了 Python 以及其它脚本语言这里,可以直接在壳里运行,但最大的问题是运行可以运行,无法保存,要保存就又要跟传统方式一样,找个编辑器来,或者 vi ,存成文件以后才可以运行。 Jupyter 最大的优点就是:它本身还是一个外壳环境,可以运行脚本,但同时也帮你自动把这些脚本代码保存了下来,不但保存脚本代码,并且你插在脚本代码当中的所有注释不是普通注释,而是各种格式化的 Markdown 都一并帮你保存下来,并且可以随时修改。所以它兼具了脚本外壳和文件管理系统的优点,从此你开发 Python 代码再也不用先在IDE里写好代码,然后再到终端里去运行,而直接在一个 web 页面上就全部搞定了。 Java 有这样的工具吗? PHP 有这样的工具吗?没有,所以我们必须选择 Python 。 Pandas 第二神器是 Pandas 。如果我让你读取一个 csv…