曾经连续几个月关注它就为了等它降价几十块,还没买回来就已经幻想好日日夜夜与它形影不离,当它真的闯入你的生活,你不禁感叹:真香!(用Kindle盖出来的泡面真香)


甚至官方都开始自嘲用kindle盖过的泡面会更香,你的Kindle还好吗?还是说你已经一边用电脑看书一边用Kindle盖泡面了?
思路梳理
本文不会通过介绍热门书籍的方式让你重新拿起Kindle,而是教你如何将自己喜欢的网络小说放进你的Kindle。
PS:本文涉及专业性知识较多,如过你并没有接触过Python和爬虫,请直接在评论区留言小说名,我有时间会帮你制书。
- 在小说网站找到你喜欢的网络小说,使用Python爬虫爬取每一章小说的内容
- 将爬取到的内容按章节区分,使用csv格式保存并排序
- python读取csv文件并按照制书软件要求的格式将其装化成txt文件
- 使用制书软件将txt文件制成mobi格式的电子书
- 将书籍导入Kindle(邮箱推送或者连电脑通过usb传输)
书籍抓取
本节涉及到技术:Python, Scrapy
现在网上各类小说网站层出不穷,我们要做的就是在这些小说网站中找到想看的书籍并保存到本地。
确定网站
1、网站路由:每一章页面url最好是https://[域名]/[小说标识]/[章节标识].html,便于抓取;章节标识最好是有序数字(可以不连续),便于章节排序。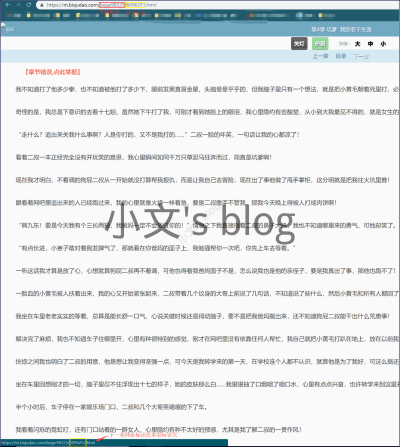

2、防爬虫机制:最好找那些没有防爬虫机制的网站,会大大加快我们爬取速度。
本站使用的示例网站是:m.biqudao.com
工具安装
python环境下,使用安装scrapy库,然后使用scrapy命令创建和编写爬虫。
|
1 |
pip install scrapy |
如果遇到安装错误,可能是要手动下载安装Twisted依赖。
开始爬取
我写的爬虫文件如下,可供参考。爬取速度大概1秒10章
https://github.com/qcgzxw/scrapy
|
1 |
scrapy crawl biqudao -o qcgzxw.csv |
输出为csv文件,便于章节排序。
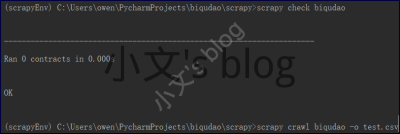
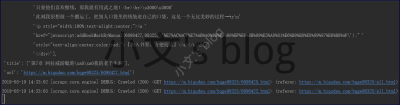
爬出来的文件时乱序

章节排序
将输出的csv文件用Excel打开,按网址排序即可。(如果内容过多,打开和排序可能会卡顿)
Excel打开乱码解决方式:使用Notpad++软件打开csv文件,点击 编码 ,转为UTF-8-BOM格式,保存后再次用Excel打开即可。
转txt文件
我使用的制书软件是calibre - E-book management,他要求的格式是用##来表示章名,所以我们从csv文件中读取并转化成对应格式的txt文件。
https://github.com/qcgzxw/scrapy/blob/master/csv2txt.py
运行该脚本即可转化成txt文本。

书籍制作
下载安装配置calibre - E-book management软件,将转换好的txt文件拉进去,然后选中,点击转换书籍。
不需要过多操作,点击确定即可开始任务
等半小时就好了,直接右键点击转换好的mobi格式的书籍,点击共享,发送邮件至***,kindle联网即可自动获取到通过邮件发送的文件了。
PS:转换过程很慢,我一本20M的书花了2小时。
效果展示


